Kubernetes
Kubernetes(常简称为K8s)是用于自动部署、扩展和管理容器化(containerized)应用程序的开源系统
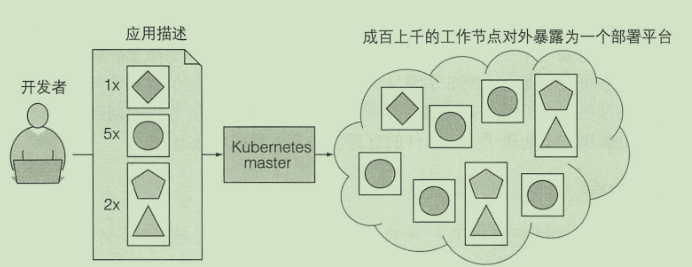
架构
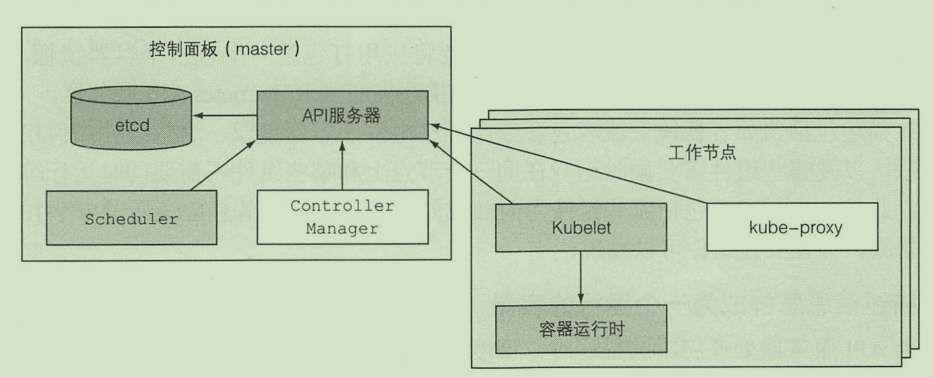
master:用于控制集群
- API服务器:外部访问入口
- Scheduler:调度应用(为应用分配工作节点)
- Controller Manager:执行集群级别的功能
- etcd:存储集群配置的分布式数据存储
工作节点:运行用户部署应用的节点
- 容器运行时:Docker 或者其他容器
- Kubelet:与API服务器通信 管理当前节点的容器
- kube-proxy:负责组件之间的负载均衡
分布式
- Kubenetes系统组件间只能通过API服务器通信
- 为了保证高可用性, master的每个组件可以有多个实例
etcd
只有API服务器才能直接与etcd通信
数据在etcd中存储的是一个层次级目录结构 末端节点存储的json数据
集群一致性保证:raft算法
API 服务器
- 认证授权
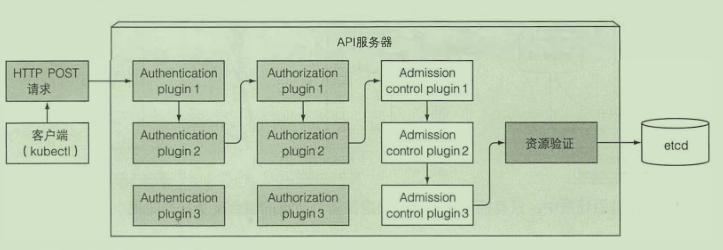
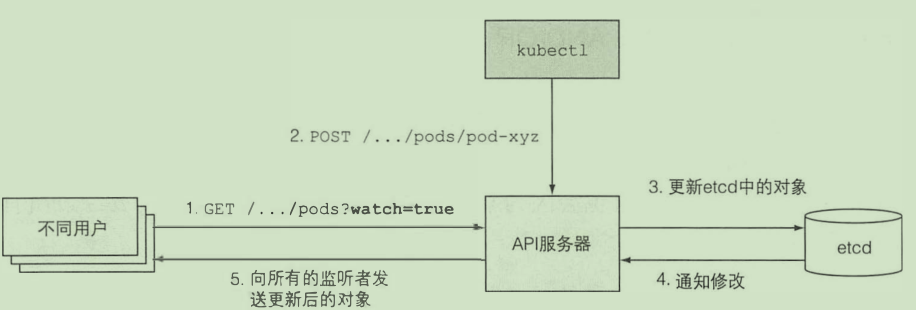
- 通知客户端资源变更
安全防护
- pod 使用 service accounts机制进行认证
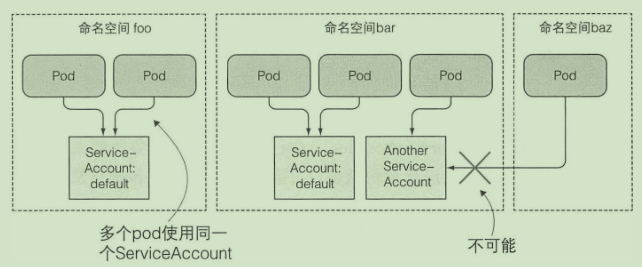
kubectl get sa # 获取服务账户
kubectl create serviceaccount foo # 创建
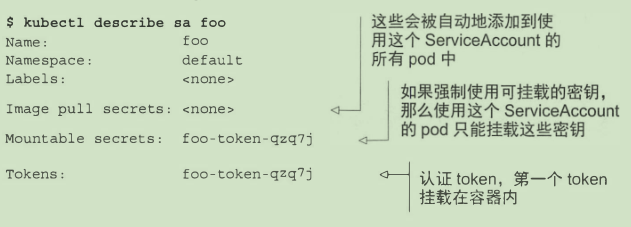
- 使用sa:
spec:
serviceAccountName: foo
RBAC控制:使用插件
调度器
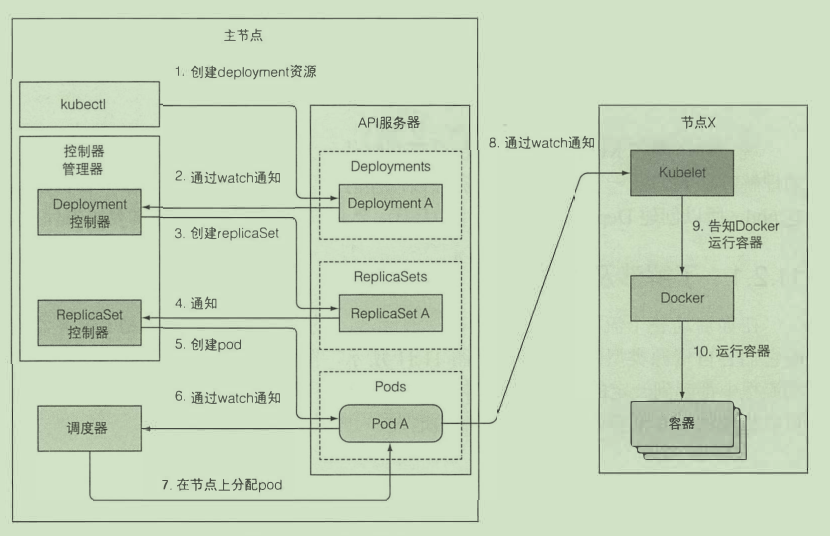
利用 API 服务器的监听机制等待新创建的 pod, 然后给每个新的、 没有节点集的 pod 分配节点
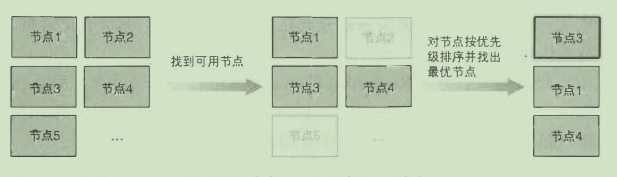
调度过程是很复杂的:
- 选择可用节点
- 选择最佳节点
- 高级调度
- 如何保证节点副本分布尽可能均匀
控制管理器
确保系统真实状态朝 API 服务器定义的期望的状态收敛
- rc rs控制器 deployment控制器...
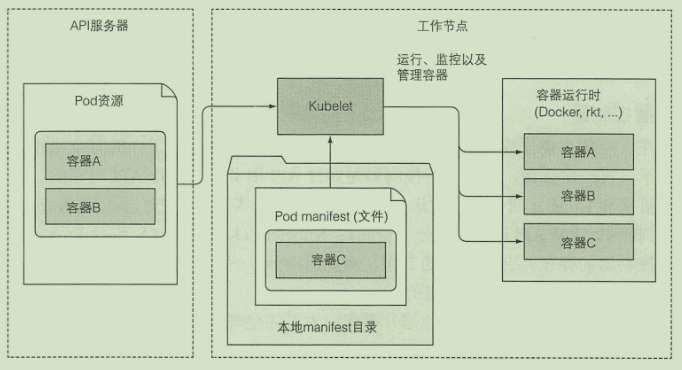
Kubelet
- 在 API 服务器中创建Node 资源, 等待pod分配给它并启动pod
- 向API服务器提供监控
- 当pod从 API服务器删除, kubelet也会删除pod
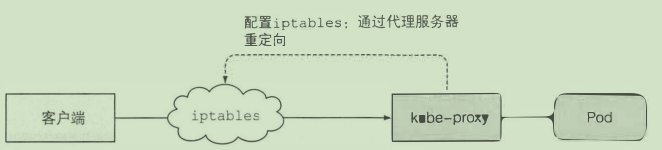
kube-proxy
确保用户可以访问后端的pod
两种模式:

控制器协作
pod 到底是什么
网络
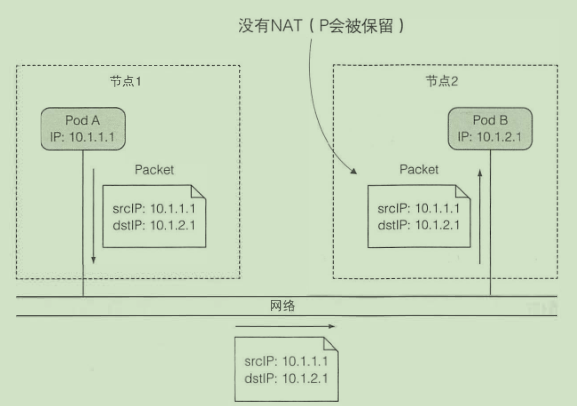
相同节点的pod通信:
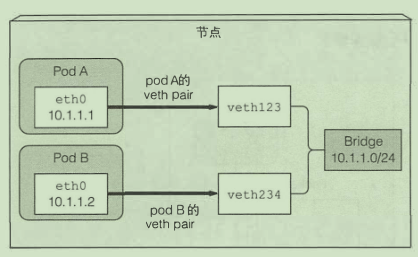
不同节点的pod通信:
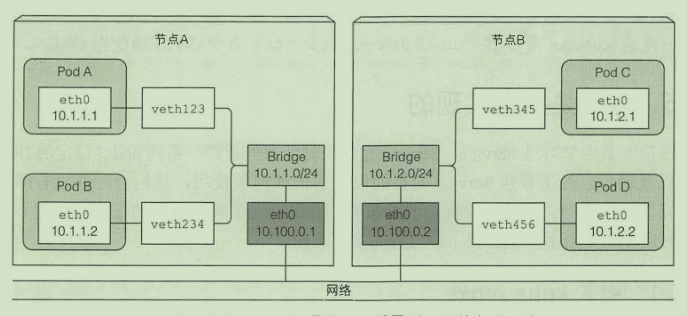
只有当所有节点连接到相同网关的时候 上述方案才有效
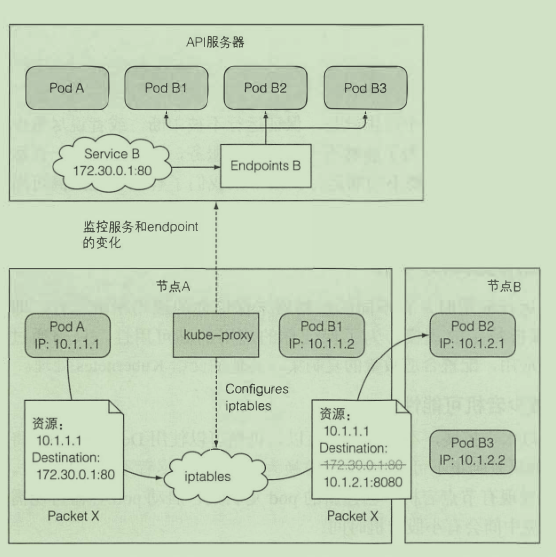
服务的实现
服务暴露的外部ip与端口通过每个节点上的kube-proxy实现
暴露的这个ip是虚拟的 主要是用来做映射用的 当kube-proxy接收到这个ip的请求 就会查找映射 转发请求
高可用集群
应用高可用:
- 水平扩展
- 主从架构
master高可用:
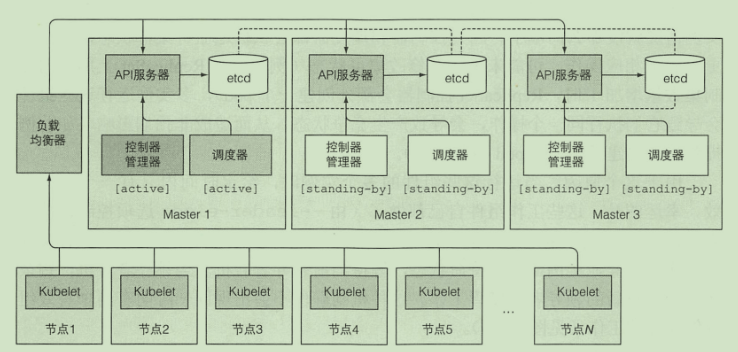
- etcd自身会进行数据同步
- API 服务器是无状态的
- 控制器与调度器会进行主从选举 只有leader才会进行调度控制工作
优点
- 简化部署
- 充分利用硬件
- 健康检查 自修复
- 自动扩容
在K8S中运行应用
根据描述信息生成对应的pod 在pod中运行容器
K8S会保证集群中的容器数量实例 在容器死亡时 会启动新容器替补
K8S 在运行时可根据需求动态调整副本数量
通过kube-proxy能进行服务连接动态切换
本地运行K8S
- 安装minikube
- 安装kubectl
minikube start \
--image-mirror-country=cn \
--registry-mirror='https://t9ab0rkd.mirror.aliyuncs.com' \
--image-repository='registry.cn-hangzhou.aliyuncs.com/google_containers'
部署第一个应用
kubectl run kubia --image=luksa/kubia --port=8080 # 创建容器运行
kubectl get pods # 获取pod
kubectl get rc
kubectl port-forward kubia 8080:8080 # 开启端口转发
kubectl get pods -o wide # 查看应用在哪个节点
kubectl scale rc kubia --replicas=3 # 水平扩容
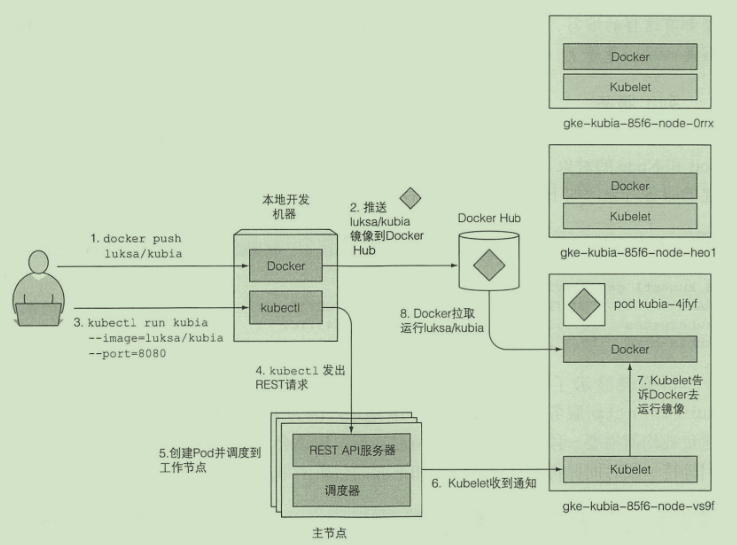
逻辑架构:
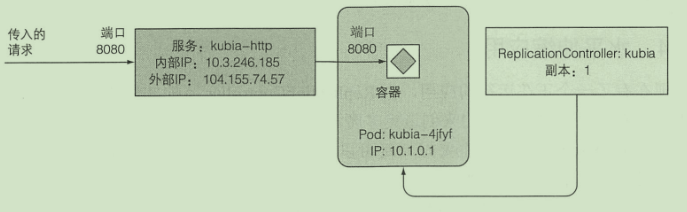
- RC用来确保始终有pod运行
- 使用http服务来完成外部请求到pod的映射
pod
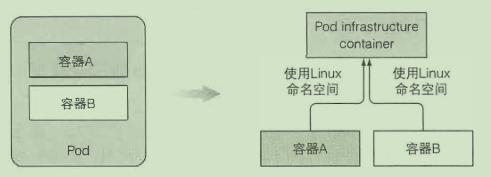
一组紧密相关的容器 独立的逻辑机器
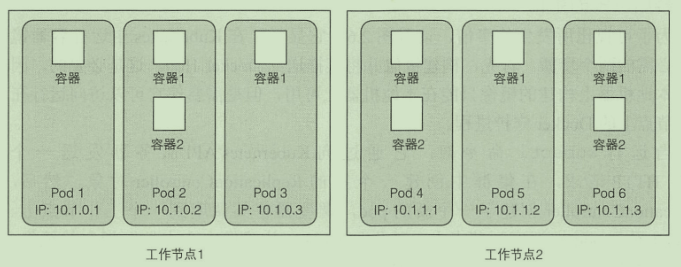
一 个 pod 中的所有容器都在相同的 network 和 UTS 命名空间下运行
每个 pod 都有自己的 IP 地址, 并且可以通过这个专门的网络实现 pod 之间互相访问
pod的使用:
- 倾向于单个pod单个容器
使用yml创建pod
apiVersion: v1
kind: Pod
metadata:
name: kubia-manual
labels:
env: test # 指定一个标签
spec:
nodeSelector: # 选择特定标签的节点
super: "true"
containers:
- image: luksa/kubia
name: kubia
ports:
- containerPort: 8080
protocol: TCP
kubectl create -f kubia-manual.yaml
kubectl logs kubia-manual # 查看日志
标签
kubectl get po --show-labels
kubectl label po kubia-manual createtion_method=manual # 修改标签
kubectl label node minikube super=true
kubectl get po -l createtion_method=manual # 根据标签筛选
注解
注解也是键值对
kubectl annotate pod kubia-manual wang.ismy/name="cxk"
命名空间
命名空间简单为对象划分了一个作用域
kubectl get ns
kubectl get po -n kube-system # 获取命名空间下的pod
kubectl create namespace custom-namespace # 创建命名空间
kubectl create -f kubia-manual.yaml -n custom-namespace # 指定命名空间
停止与移除
kubectl delete po kubia-manual # 根据名字删除
副本机制
k8s 会保证 pod 以及 容器的健康运行
存活探针
当存活探针探测失败 容器就会重启
- 创建
apiVersion: v1
kind: Pod
metadata:
name: kubia-liveness
spec:
containers:
- image: luksa/kubia-unhealthy
name: kubia
livenessProbe: # 存活探针
httpGet: # 返回2xx 或者 3xx就代表活着
path: /
port: 8080
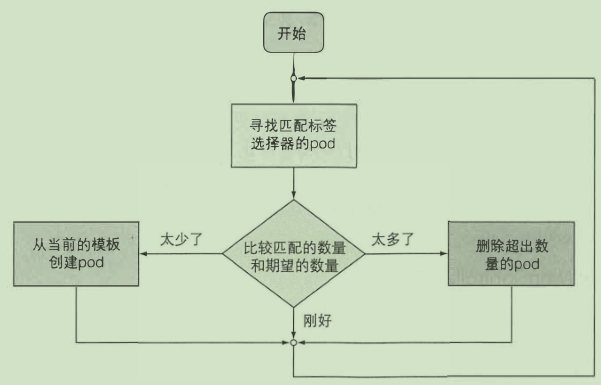
ReplicationController
创建和管理一个pod的多个副本
- 创建
apiVersion: v1
kind: ReplicationController
metadata:
name: kubia
spec:
replicas: 3
selector:
app: kubia
template:
metadata:
labels:
app: kubia
spec:
containers:
- name: kubia
image: luksa/kubia
ports:
- containerPort: 8080
控制器通 过 创建 一 个新的替代pod来响应pod的删除操作
通过更改标签的方式来实现rc与pod的关联
- 扩容
kubectl scale rc kubia --replicas=10
- 删除
kubectl delete rc kubia
ReplicaSet
ReplicaSet 会 替代 rc
rs 的pod 选择器的表达能力更强
- 创建
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: kubia
spec:
replicas: 3
selector:
matchLabels:
app: kubia
template:
metadata:
labels:
app: kubia
spec:
containers:
- name: kubia
image: luksa/kubia
DaemonSet
由DaemonSet 创建的pod 会绕过调度程序 会在所有集群节点上运行(或者也可以通过指定nodeSelector在其他节点运行)
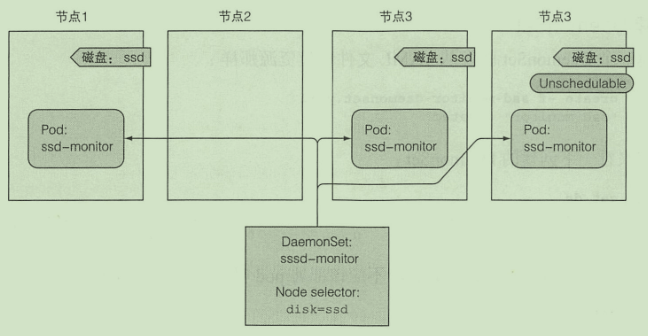
- 创建
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: ssd-monitor
spec:
selector:
matchLabels:
app: ssd-monitor
template:
metadata:
labels:
app: ssd-monitor
spec:
nodeSelector:
disk: ssd
containers:
- name: main
image: luksa/ssd-monitor
Job
允许运行 一 种 pod, 该 pod 在内部进程成功结束时, 不重启容器。
- 创建
apiVersion: batch/v1
kind: Job
metadata:
name: batch-job
spec:
completions: 5 # 运行pod数
parallelism: 2 # 并行运行数
template:
metadata:
labels:
app: batch-job
spec:
restartPolicy: OnFailure
containers:
- name: main
image: luksa/batch-job
CronJob
- 创建
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: cron-job
spec:
schedule: "0,15,30,45 * * * *"
jobTemplate:
spec:
template:
metadata:
labels:
app: batch-job
spec:
restartPolicy: OnFailure
containers:
- name: main
image: luksa/batch-job
服务
是一种为一组功能相同的 pod 提供单一不变的接入点的资源
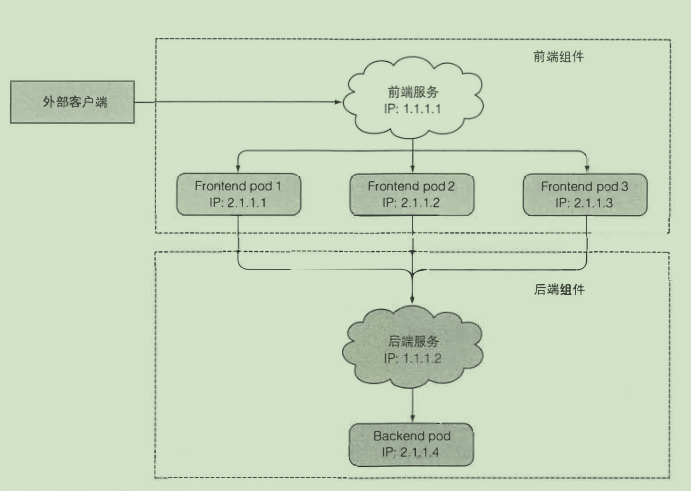
- 创建
apiVersion: v1
kind: Service
metadata:
name: kubia
spec:
ports:
- port: 80
targetPort: 8080
selector:
app: kubia
服务间的发现
- 通过环境变量
kubectl exec kubia-9knkg -- env
- 通过DNS
域名:kubia.default.svc.cluster.local
如果在同一命名空间下 直接使用 kubia即可
Endpoint
暴露一个服务的 IP 地址和端口的列表
kubectl get endpoints kubia
暴露服务给外部
- NodePort:每个集群节点都会在节点上打开一个端口 将在该端口上接收到的流量重定向到基础服务
apiVersion: v1
kind: Service
metadata:
name: kubia-nodeport
spec:
type: NodePort
ports:
- port: 80
targetPort: 8080
nodePort: 30123
selector:
app: kubia
通过nodeip:30123 访问
- 负载均衡器将流量重定向到跨所有节点的节点端口。客户端通过负载均衡器的 IP 连接到服务
apiVersion: v1
kind: Service
metadata:
name: kubia-loadbalancer
spec:
type: LoadBalancer
ports:
- port: 80
targetPort: 8080
selector:
app: kubia
通过externalip:一个随机端口访问
- Ingress 只需要 一 个公网 IP 就能为许多服务提供访问
启用:
minikube addons enable ingress
就绪探针
- 创建
# kubia-rc.yaml
spec:
containers:
- name: kubia
image: luksa/kubia
readinessProbe:
exec:
command:
- ls
- /var/ready # 该文件存在 容器才被认为就绪
服务故障排除
- 确保从集群内连接到服务的集群IP
- 服务的集群IP 是虚拟IP, 是无法ping通的
- 如果已经定义了就绪探针, 请确保 它返回成功;否则该pod不会成为服务的一部分
- 确认某个容器是服务的 一 部分
- 检查是否连接到服务公开的端口,而不是目标端口
- 尝试直接连接到podIP以确认pod正在接收正确端口上的 连接
- 法通过pod的IP 访问应用, 请确保应用不是仅绑定 到本地主机
卷
卷是 pod 的 一 个组成部分, 因此像容器 一 样在 pod 的规范中定义
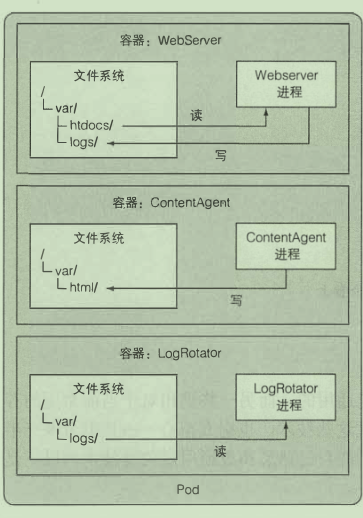
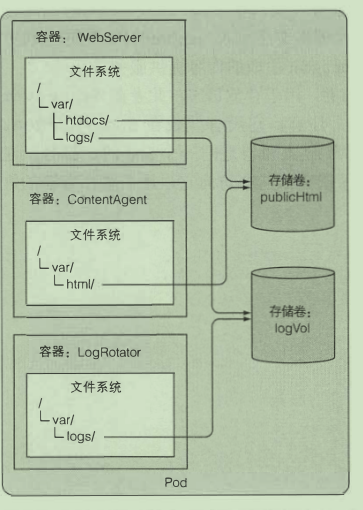
在容器之间共享数据
emptyDir:pod被删除时 卷的内容就会丢失
- 创建
apiVersion: v1
kind: Pod
metadata:
name: fortune
spec:
containers:
- image: luksa/fortune
name: html-genrator
volumeMounts:
- name: html
mountPath: /var/htdocs
- image: nginx:alpine
name: web-server
volumeMounts:
- name: html # 使用html卷
mountPath: /usr/share/nginx/html # 挂载到容器的位置
readOnly: true
ports:
- containerPort: 80
protocol: TCP
volumes: # 创建一个卷
- name: html
emptyDir: {}
gitRepo:以git仓库文件填充目录文件
apiVersion: v1
kind: Pod
metadata:
name: gitrepo-volume-pod
spec:
containers:
- image: nginx:alpine
name: web-server
volumeMounts:
- name: html
mountPath: /usr/share/nginx/html
readOnly: true
ports:
- containerPort: 80
protocol: TCP
volumes:
- name: html
gitRepo:
repository: https://github.com/luksa/kubia-website-example.git
revision: master
directory: .
访问工作节点文件
hostPath 卷指向节点文件系统上的特定文件或目录
持久化存储
- gce持久盘
- aws弹性块存储
- nfs卷
持久卷
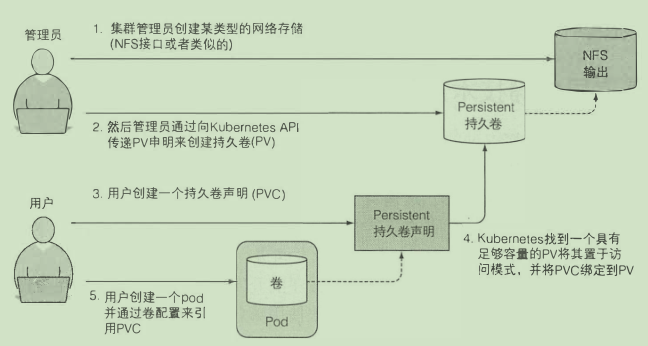
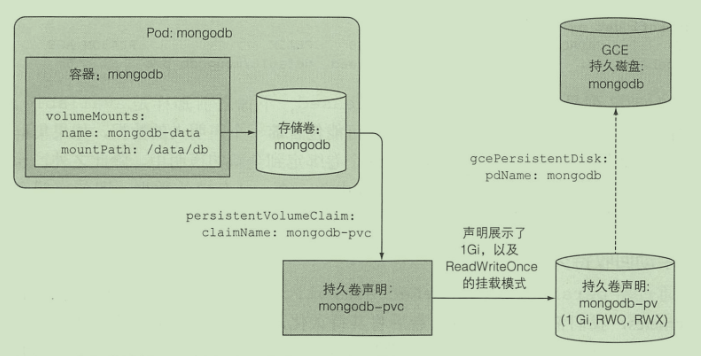
- 创建持久卷
apiVersion: v1
kind: PersistentVolume
metadata:
name: mongodb-pv
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
- ReadOnlyMany
persistentVolumeReclaimPolicy: Retain
hostPath:
path: /tmp/mongodb
- 创建持久卷声明
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mongodb-pvc
spec:
resources:
requests:
storage: 1Gi
accessModes:
- ReadWriteOnce
storageClassName: "" # 动态持久卷
- 容器使用持久卷
# ...
volumes:
- name: mongodb-data
persistentVolumeClaim:
claimName: mongodb-pvc
动态持久卷
- 创建StorageClass
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: fast
provisioner: k8s.io/minikube-hostpath
parameters:
type: pd-ssd
声明是通过名称引用它的 方便之处主要是在不同集群之间移植
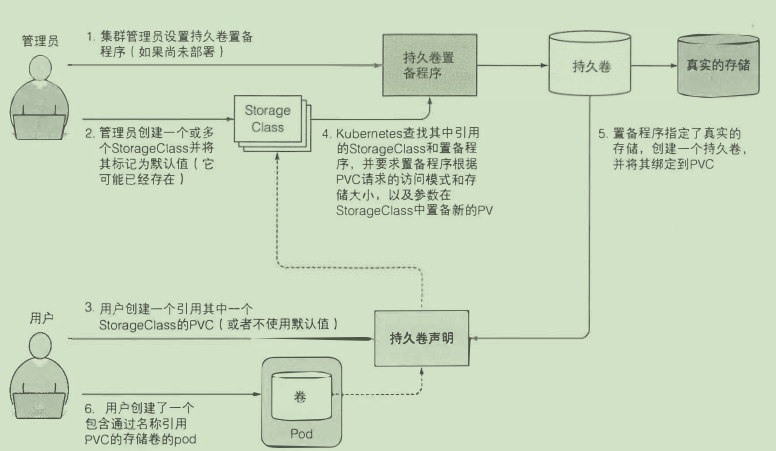
参数配置
通过定义传递参数:
- image: luksa/fortune:args
args: ["2"]
使用环境变量:
- image: luksa/fortune:env
env:
- name: INTERVAL
value: "30"
ConfigMap
类似于配置中心:
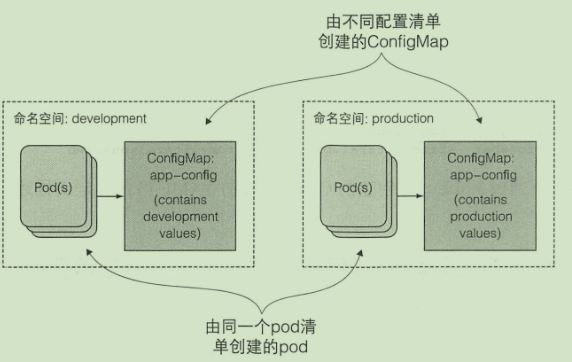
- 创建
kubectl create configmap fortunes-config --from-literal=sleep-interval=25
- 单个环境变量使用
- image: luksa/fortune:env
env:
- name: INTERVAL
valueFrom:
configMapKeyRef:
name: fortunes-config
key: sleep-interval
- 一次传递所有环境变量
- image: luksa/fortune:env
env:
envFrom:
- prefix: CONFIG_
configMapRef:
name: fortunes-config
args: ["${CONFIG_xxx}"] # 传递到命令行
- 挂载到卷
volumes:
- name: config
configMap:
name: configmap
- 更新配置
kubectl edit configmap xxx
Secret
存储与分发敏感信息
- 创建
kubectl create secret generic fortune-https --from-file=https.key
- 挂载卷使用
- image: xxx
volumeMounts:
- name: keys
mountPath: /etc/nginx/keys/
volumes:
- name: keys
secret:
secretName: fortune-https
- 环境变量使用
env:
- name: FOO_SECRET
valueFrom:
secretKeyRef:
name: fortune-https
key: name
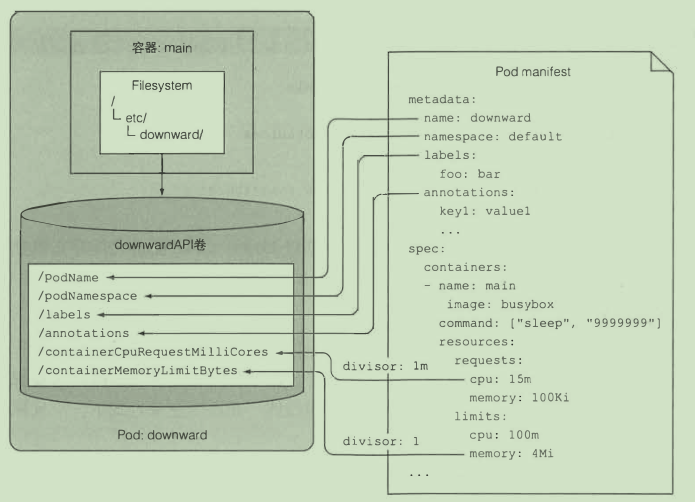
pod 元数据访问
Downward API
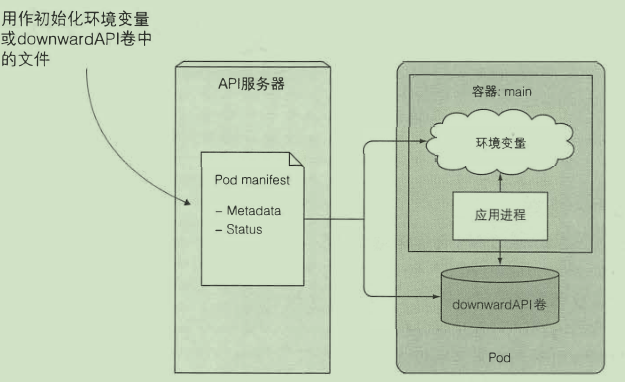
通过环境变量:
env:
- name: POD IP
valueFrom:
fieldRef:
fieldPath: status.podIP
- name: CONTAINER CPU REQUEST MILLICORES
valueFrom:
resourceFieldRef:
resource: requests.cpu
divisor: lm
通过卷:
volumes:
- name: downward
downwardAPI:
items:
- path: "podName"
fieldRef:
fieldPath: metadata.name
使用 K8S API 服务器
REST API:
- 启动kubectl proxy
curl http://localhost:8001/apis/batch/v1/jobs
在 pod 内部使用
客户端API
Deployment
更新应用:
- 删除旧版本pod 启动新版本pod
- 会造成短暂的服务不可用
- 启动新版本pod 删除旧版本pod
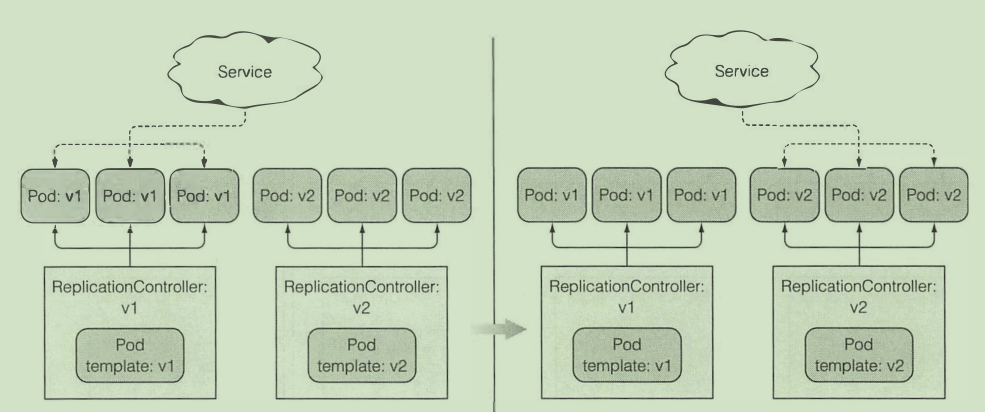
使用rc进行滚动升级
书上通过rolling-update的方法已经过时
使用 Deployment 声明式升级
- 创建
apiVersion: apps/v1
kind: Deployment
metadata:
name: kubia
spec:
replicas: 3
selector:
matchLabels:
app: kubia
template:
metadata:
name: kubia
labels:
app: kubia
spec:
containers:
- image: luksa/kubia:v1
name: nodejs
kubectl create -f kubia-dep-v1.yaml --record # 加上该参数会记录历史版本号
- 更新版本
kubectl set image deployment kubia nodejs=luksa/kubia:v2
- 回滚
kubectl rollout undo deployment kubia
使用 - -to-revision=xxx 回滚到特定版本
- 升级速率控制
rollingUpdate :
maxSurge: 1 # 最多允许超过的副本数
maxunavailable: 0 # 最多允许多少百分比pod不可用
使用rollout pause 暂停滚动升级 部分软件版本就不一样 金丝雀发布
minReadySeconds属性指定新创建的pod至少要成功运行多久之后 , 才能 将其视为可用
如果 一 个新的pod 运行出错, 并且在minReadySeconds时间内它的就绪探针出现了失败, 那么新版本的滚动升级将被阻止
- 使用kubectl apply升级Deployment
StatefulSet
如何复制有状态的pod?
Statefulset 保证了pod在重新调度后保留它们的标识和状态
每个pod都有专属于它的持久卷
K8S保证不会有两个相同标识和持久卷的pod同时运行
使用
- 创建持久卷
- 创建控制 Service
apiVersion: v1
kind: Service
metadata:
name: kubia
spec:
clusterIP: None
selector:
app: kubia
ports:
- name: http
port: 80
- 创建StatefulSet
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: kubia
spec:
serviceName: kubia
replicas: 2
selector:
matchLabels:
app: kubia # has to match .spec.template.metadata.labels
template:
metadata:
labels:
app: kubia
spec:
containers:
- name: kubia
image: luksa/kubia-pet
ports:
- name: http
containerPort: 8080
volumeMounts:
- name: data
mountPath: /var/data
volumeClaimTemplates:
- metadata:
name: data
spec:
resources:
requests:
storage: 1Mi
accessModes:
- ReadWriteOnce
- 使用一个 Service 来访问 Pod
apiVersion: v1
kind: Service
metadata:
name: kubia-public
spec:
selector:
app: kubia
ports:
- port: 80
targetPort: 8080
发现伙伴节点
- 容器内部通过DNS SRV 记录
安全
pod 使用宿主节点的Linux命名空间
- 使用宿主节点的网络命名空间
spec:
hostNetwork: true
- 使用宿主节点的端口而不使用宿主节点的网络命名空间
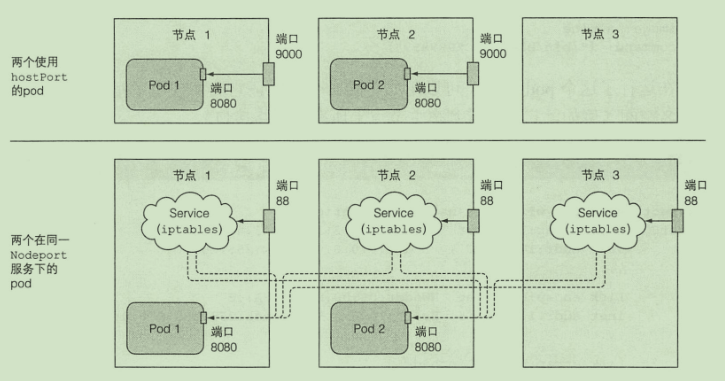
如果使用hostport 一个节点只能有一个相同的pod
- 使用宿主的PID与IPC空间
spec:
hostPID: true
hostIPC: true
开启后 相同节点的pod的进程之间就是可见的 可通信的
安全上下文
spec:
securityContext:
# ... pod 级别的
containers:
securityContext:
runAsUser: 405 # 以指定用户运行
runAsNonRoot: true # 禁止以root运行
privileged: true # 在特权模式下允许
capabilities:
add:
- SYS_TIME # 开放硬件时间修改权限
drop:
- CHOWN # 禁用文件所有者修改权限
readOnlyRootFilesystem: true # 禁止在根目录写文件
pod 网络隔离
- 网络策略
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: postgres-netpolicy
spec:
podSelector:
matchLabels:
app: database # 对该标签的pod生效
ingress: # 只允许来自匹配下面标签的pod请求
- from:
- podSelector:
matchLabels:
app: webserver
ports:
- port: 5432
计算资源管理
申请资源
spec:
containers:
- image: busybox
command: ["dd", "if=/dev/zero", "of=/dev/null"]
name: main
resources:
requests:
cpu: 200m # 申请200毫核 也就说20%CPU
memory: 10Mi # 申请10M内存
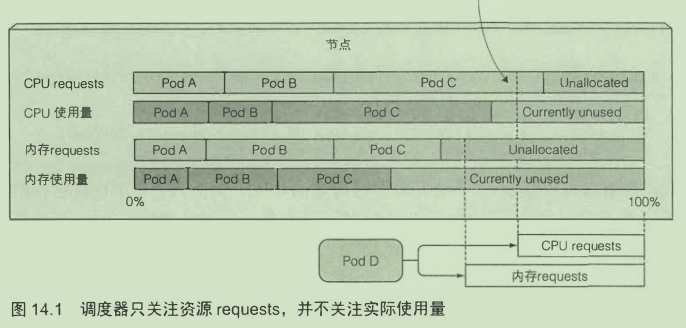
添加了requests对调度的影响:
通过设置资源requests我们指定了pod对资源需求的最小值。
调度器不关心资源的实际使用了 而是关心各pod所定义的requests资源量
限制资源
resources:
limits:
cpu: 1 # 允许最大使用1核
memory: 20Mi # 内存允许最大 20M
超过limits的情况:
- cpu:进程分配到的CPU不会超过指定的
- 内存:如果内存超过limit 则容器会被杀掉
QoS 等级
通过定义优先级决定资源不足时杀谁
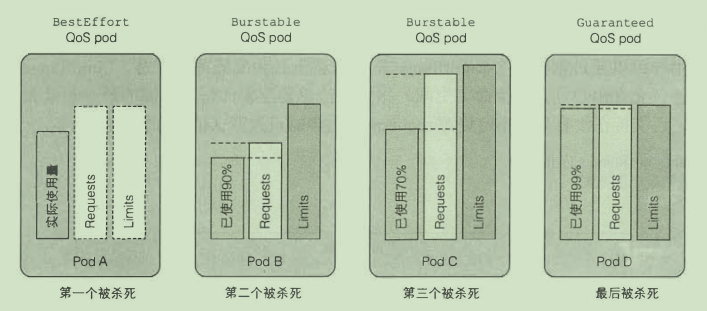
- BestEffort 优先级最低
- 没有设置requess和limits都属于这个级别
- Guaranteed 优先级最高
- cpu和内存都要设置requests 和 limits
- 所有容器都要设置资源量
- requests 与 limits必须相等
- Burstable 其他的pod都属于这个等级
限制命名空间中的pod
- LimitRange插件
- ResourceQuota
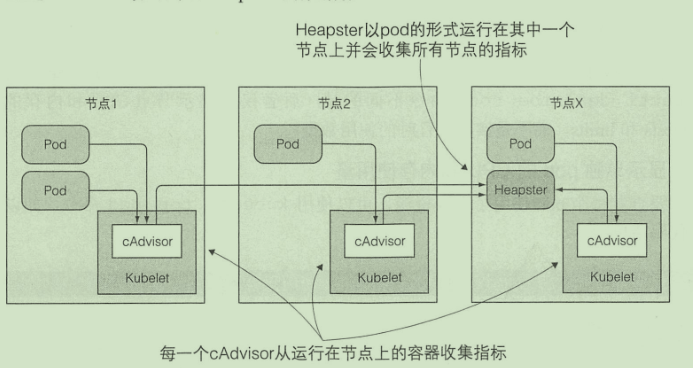
监控 pod
- Heapster
自动伸缩与集群
- 基于CPU使用率的自动伸缩
kubectl autoscale deployment kubia --cpu-percent=30 --min=1 --max=5
- 纵向扩容
自动修改CPU与内存大小
集群节点扩容
新节点启动后,其上运行的Kubelet会联系API服务器,创建 一 个Node资源以注册该节点
当一 个节点被选中下线,它首先会被标记为不可调度, 随后运行其上的pod 将被疏散至其他节点
高级调度
污点和容忍度
限制哪些pod可以被调度到某 一 个节点
kubectl describe node minikube | grep Taints # 查看节点污点
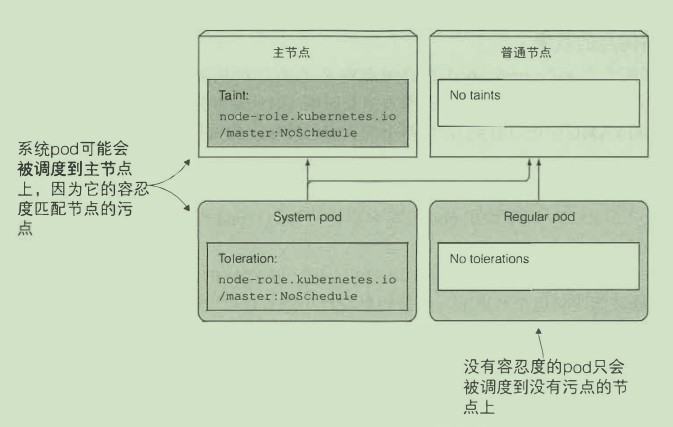
NoSchedule 表示如果 pod 没有容忍这些污点, pod 则不能被调度到包含这些污点的节点上
PreferNoSchedule 是 NoSchedule 的 一 个宽松的版本, 表示尽量阻止pod 被调度到这个节点上, 但是如果没有其他节点可以调度, pod 依然会被调度到这个节点上
NoExecute会影响正在节点上运行着的 pod 。 如果在 一 个节点上添加了 NoExecute 污点, 那些在该节点上运行着的pod, 如果没有容忍这个 NoExecute 污点, 将会从这个节点去除
添加污点
kubectl taint node minikube node-type=production:NoSchedule
- pod添加容忍度
spec:
replicas: 5
template:
spec:
...
tolerations:
- key: node-type
operator: Equal
value: production
effect: NoSchedule
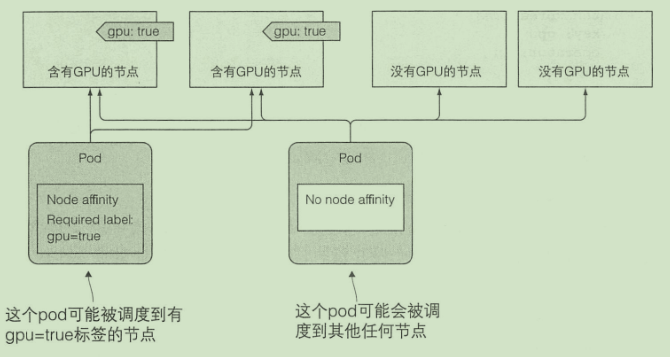
节点亲缘性
这种机制允许你通知 Kubemetes将 pod 只调度到某个几点子集上面
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: gpu
operator: In
values:
- "true"
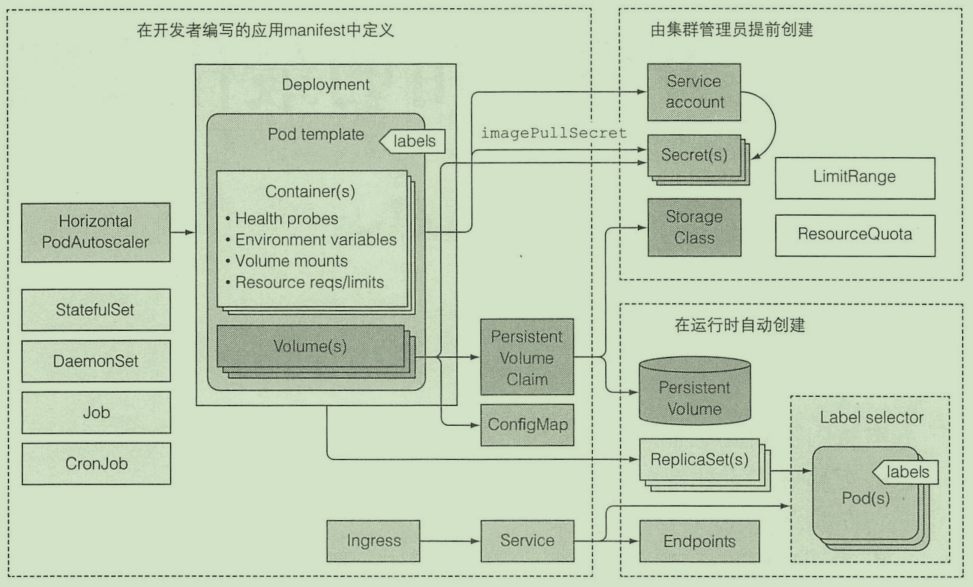
最佳实践
pod 的生命周期
- 应用必须意识到会被杀死或者重新调度
- ip与主机名会发生变化
- 使用卷解决数据写入问题
- 不断重启的pod不会被重新调度
- 固定顺序启动pod
- 使用init容器
- 应用要处理好其他依赖没有准备好的情况
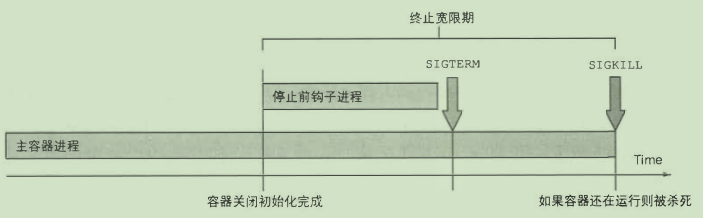
- 生命周期钩子
- postStart
- preStop
- pod的关闭
客户端请求处理
- pod启动时避免客户端连接断开
- 使用一个就绪探针来探测pod是否准备好接受请求了
- pod关闭时避免请求断开
- 停止接受新连接
- 等待所有请求完成
- 关闭应用
让应用方便运行与管理
- 可管理的容器镜像
- 镜像太大难以传输 镜像太小会缺失很多工具
- 合理给镜像打标签
- 不要使用latest 使用具体版本号
- 使用多维度的标签
- 使用注解描述额外信息
- 使用/dev/termination-log 写入失败信息
- 日志
- 将日志打印到标准输出方便查看
- 集中式日志系统
应用扩展
CRD对象
- 创建
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: websites.extensions.example.com
spec:
scope: Namespaced
group: extensions.example.com
version: v1
names:
kind: Website
singular: website
plural: websites
- 创建CRD实例
apiVersion: extensions.example.com/v1
kind: Website
metadata:
name: kubia
spec:
gitRepo: https://github.com/luksa/kubia-website-example.git
服务目录
服务目录就是列出所有服务的目录。 用户可以浏览目录并自行设置目录中列出的服务实例